sources
 Subscribe
Subscribe OPML
OPMLPowered by Perlanet
-
ebaf15d🟩 Aphra is up (200 in 190 ms) [skip ci] [upptime]
-
594c17e🟩 Klortho is up (200 in 757 ms) [skip ci] [upptime]
- 10 more commits »

 The team explore one of the newest areas of modern astronomy, the search for exoplanets, the distant worlds that orbit stars beyond our own solar system.
The team explore one of the newest areas of modern astronomy, the search for exoplanets, the distant worlds that orbit stars beyond our own solar system.  Bliss and Book's investigation into Harkup's death continues as Book discovers some surprising evidence in the case of the bombsite skeletons.
Bliss and Book's investigation into Harkup's death continues as Book discovers some surprising evidence in the case of the bombsite skeletons.  In 1989, Daniel is left reeling and heartbroken at Alison's sudden disappearance. In 2015, a surprise betrayal takes Daniel by surprise, but he has to fight for what he loves.
In 1989, Daniel is left reeling and heartbroken at Alison's sudden disappearance. In 2015, a surprise betrayal takes Daniel by surprise, but he has to fight for what he loves.  In 1989, Alison's home life goes from bad to worse as she takes on caring for Peter. In 2015, Daniel struggles with Alison's revelations of what occurred during their relationship twenty years ago.
In 1989, Alison's home life goes from bad to worse as she takes on caring for Peter. In 2015, Daniel struggles with Alison's revelations of what occurred during their relationship twenty years ago. 
Watched on Sunday July 13, 2025.

Watched on Saturday July 12, 2025.

Watched on Friday July 11, 2025.

Watched on Tuesday July 8, 2025.

Watched on Sunday July 6, 2025.
Recently, Gabor ran a poll in a Perl Facebook community asking which version of Perl people used in their production systems. The results were eye-opening—and not in a good way. A surprisingly large number of developers replied with something along the lines of “whatever version is included with my OS.”
If that’s you, this post is for you. I don’t say that to shame or scold—many of us started out this way. But if you’re serious about writing and running Perl in 2025, it’s time to stop relying on the system Perl.
Let’s unpack why.
What is “System Perl”?
When we talk about the system Perl, we mean the version of Perl that comes pre-installed with your operating system—be it a Linux distro like Debian or CentOS, or even macOS. This is the version used by the OS itself for various internal tasks and scripts. It’s typically located in /usr/bin/perl and tied closely to system packages.
It’s tempting to just use what’s already there. But that decision brings a lot of hidden baggage—and some very real risks.
Which versions of Perl are officially supported?
The Perl Core Support Policy states that only the two most recent stable release series of Perl are supported by the Perl development team [Update: fixed text in previous sentence]. As of mid-2025, that means:
-
Perl 5.40 (released May 2024)
-
Perl 5.38 (released July 2023)
If you’re using anything older—like 5.36, 5.32, or 5.16—you’re outside the officially supported window. That means no guaranteed bug fixes, security patches, or compatibility updates from core CPAN tools like ExtUtils::MakeMaker, Module::Build, or Test::More.
Using an old system Perl often means you’re several versions behind, and no one upstream is responsible for keeping that working anymore.
Why using System Perl is a problem
1. It’s often outdated
System Perl is frozen in time—usually the version that was current when the OS release cycle began. Depending on your distro, that could mean Perl 5.10, 5.16, or 5.26—versions that are years behind the latest stable Perl (currently 5.40).
This means you’re missing out on:
-
New language features (
builtin,class/method/field,signatures,try/catch) -
Performance improvements
-
Bug fixes
-
Critical security patches
- Support: anything older than Perl 5.38 is no longer officially maintained by the core Perl team
If you’ve ever looked at modern Perl documentation and found your code mysteriously breaking, chances are your system Perl is too old.
2. It’s not yours to mess with
System Perl isn’t just a convenience—it’s a dependency. Your operating system relies on it for package management, system maintenance tasks, and assorted glue scripts. If you install or upgrade CPAN modules into the system Perl (especially with cpan or cpanm as root), you run the risk of breaking something your OS depends on.
It’s a kind of dependency hell that’s completely avoidable—if you stop using system Perl.
3. It’s a barrier to portability and reproducibility
When you use system Perl, your environment is essentially defined by your distro. That’s fine until you want to:
-
Move your application to another system
-
Run CI tests on a different platform
-
Upgrade your OS
-
Onboard a new developer
You lose the ability to create predictable, portable environments. That’s not a luxury—it’s a requirement for sane development in modern software teams.
What you should be doing instead
1. Use perlbrew or plenv
These tools let you install multiple versions of Perl in your home directory and switch between them easily. Want to test your code on Perl 5.32 and 5.40? perlbrew makes it a breeze.
You get:
-
A clean separation from system Perl
-
The freedom to upgrade or downgrade at will
-
Zero risk of breaking your OS
It takes minutes to set up and pays for itself tenfold in flexibility.
2. Use local::lib or Carton
Managing CPAN dependencies globally is a recipe for pain. Instead, use:
-
local::lib: keeps modules in your home directory. -
Carton: locks your CPAN dependencies (likenpmorpip) so deployments are repeatable.
Your production system should run with exactly the same modules and versions as your dev environment. Carton helps you achieve that.
3. Consider Docker
If you’re building larger apps or APIs, containerising your Perl environment ensures true consistency across dev, test, and production. You can even start from a system Perl inside the container—as long as it’s isolated and under your control.
You never want to be the person debugging a bug that only happens on production, because prod is using the distro’s ancient Perl and no one can remember which CPAN modules got installed by hand.
The benefits of managing your own Perl
Once you step away from the system Perl, you gain:
-
Access to the full language. Use the latest features without backports or compatibility hacks.
-
Freedom from fear. Install CPAN modules freely without the risk of breaking your OS.
-
Portability. Move projects between machines or teams with minimal friction.
-
Better testing. Easily test your code across multiple Perl versions.
-
Security. Stay up to date with patches and fixes on your schedule, not the distro’s.
-
Modern practices. Align your Perl workflow with the kinds of practices standard in other languages (think
virtualenv,rbenv,nvm, etc.).
“But it just works…”
I know the argument. You’ve got a handful of scripts, or maybe a cron job or two, and they seem fine. Why bother with all this?
Because “it just works” only holds true until:
-
You upgrade your OS and Perl changes under you.
-
A script stops working and you don’t know why.
-
You want to install a module and suddenly
aptis yelling at you about conflicts. -
You realise the module you need requires Perl 5.34, but your system has 5.16.
Don’t wait for it to break. Get ahead of it.
The first step
You don’t have to refactor your entire setup overnight. But you can do this:
-
Install
perlbrewand try it out. -
Start a new project with
Cartonto lock dependencies. -
Choose a current version of Perl and commit to using it moving forward.
Once you’ve seen how smooth things can be with a clean, controlled Perl environment, you won’t want to go back.
TL;DR
Your system Perl is for your operating system—not for your apps. Treat it as off-limits. Modern Perl deserves modern tools, and so do you.
Take the first step. Your future self (and probably your ops team) will thank you.
The post Stop using your system Perl first appeared on Perl Hacks.
Recently, Gabor ran a poll in a Perl Facebook community asking which version of Perl people used in their production systems. The results were eye-opening—and not in a good way. A surprisingly large number of developers replied with something along the lines of “whatever version is included with my OS.”
If that’s you, this post is for you. I don’t say that to shame or scold—many of us started out this way. But if you’re serious about writing and running Perl in 2025, it’s time to stop relying on the system Perl.
Let’s unpack why.
What is “System Perl”?
When we talk about the system Perl, we mean the version of Perl that comes pre-installed with your operating system—be it a Linux distro like Debian or CentOS, or even macOS. This is the version used by the OS itself for various internal tasks and scripts. It’s typically located in /usr/bin/perl and tied closely to system packages.
It’s tempting to just use what’s already there. But that decision brings a lot of hidden baggage—and some very real risks.
Which versions of Perl are officially supported?
The Perl Core Support Policy states that only the two most recent stable release series of Perl are supported by the Perl development team [Update: fixed text in previous sentence]. As of mid-2025, that means:
Perl 5.40 (released May 2024)
Perl 5.38 (released July 2023)
If you’re using anything older—like 5.36, 5.32, or 5.16—you’re outside the officially supported window. That means no guaranteed bug fixes, security patches, or compatibility updates from core CPAN tools like ExtUtils::MakeMaker, Module::Build, or Test::More.
Using an old system Perl often means you’re several versions behind , and no one upstream is responsible for keeping that working anymore.
Why using System Perl is a problem
1. It’s often outdated
System Perl is frozen in time—usually the version that was current when the OS release cycle began. Depending on your distro, that could mean Perl 5.10, 5.16, or 5.26—versions that are years behind the latest stable Perl (currently 5.40).
This means you’re missing out on:
New language features (
builtin,class/method/field,signatures,try/catch)Performance improvements
Bug fixes
Critical security patches
Support: anything older than Perl 5.38 is no longer officially maintained by the core Perl team
If you’ve ever looked at modern Perl documentation and found your code mysteriously breaking, chances are your system Perl is too old.
2. It’s not yours to mess with
System Perl isn’t just a convenience—it’s a dependency. Your operating system relies on it for package management, system maintenance tasks, and assorted glue scripts. If you install or upgrade CPAN modules into the system Perl (especially with cpan or cpanm as root), you run the risk of breaking something your OS depends on.
It’s a kind of dependency hell that’s completely avoidable— if you stop using system Perl.
3. It’s a barrier to portability and reproducibility
When you use system Perl, your environment is essentially defined by your distro. That’s fine until you want to:
Move your application to another system
Run CI tests on a different platform
Upgrade your OS
Onboard a new developer
You lose the ability to create predictable, portable environments. That’s not a luxury— it’s a requirement for sane development in modern software teams.
What you should be doing instead
1. Use perlbrew or plenv
These tools let you install multiple versions of Perl in your home directory and switch between them easily. Want to test your code on Perl 5.32 and 5.40? perlbrew makes it a breeze.
You get:
A clean separation from system Perl
The freedom to upgrade or downgrade at will
Zero risk of breaking your OS
It takes minutes to set up and pays for itself tenfold in flexibility.
2. Use local::lib or Carton
Managing CPAN dependencies globally is a recipe for pain. Instead, use:
local::lib: keeps modules in your home directory.Carton: locks your CPAN dependencies (likenpmorpip) so deployments are repeatable.
Your production system should run with exactly the same modules and versions as your dev environment. Carton helps you achieve that.
3. Consider Docker
If you’re building larger apps or APIs, containerising your Perl environment ensures true consistency across dev, test, and production. You can even start from a system Perl inside the container—as long as it’s isolated and under your control.
You never want to be the person debugging a bug that only happens on production, because prod is using the distro’s ancient Perl and no one can remember which CPAN modules got installed by hand.
The benefits of managing your own Perl
Once you step away from the system Perl, you gain:
Access to the full language. Use the latest features without backports or compatibility hacks.
Freedom from fear. Install CPAN modules freely without the risk of breaking your OS.
Portability. Move projects between machines or teams with minimal friction.
Better testing. Easily test your code across multiple Perl versions.
Security. Stay up to date with patches and fixes on your schedule, not the distro’s.
Modern practices. Align your Perl workflow with the kinds of practices standard in other languages (think
virtualenv,rbenv,nvm, etc.).
“But it just works…”
I know the argument. You’ve got a handful of scripts, or maybe a cron job or two, and they seem fine. Why bother with all this?
Because “it just works” only holds true until:
You upgrade your OS and Perl changes under you.
A script stops working and you don’t know why.
You want to install a module and suddenly
aptis yelling at you about conflicts.You realise the module you need requires Perl 5.34, but your system has 5.16.
Don’t wait for it to break. Get ahead of it.
The first step
You don’t have to refactor your entire setup overnight. But you can do this:
Install
perlbrewand try it out.Start a new project with
Cartonto lock dependencies.Choose a current version of Perl and commit to using it moving forward.
Once you’ve seen how smooth things can be with a clean, controlled Perl environment, you won’t want to go back.
TL;DR
Your system Perl is for your operating system—not for your apps. Treat it as off-limits. Modern Perl deserves modern tools, and so do you.
Take the first step. Your future self (and probably your ops team) will thank you.
The post Stop using your system Perl first appeared on Perl Hacks.
Earlier this week, I read a post from someone who failed a job interview because they used a hash slice in some sample code and the interviewer didn’t believe it would work.
That’s not just wrong — it’s a teachable moment. Perl has several kinds of slices, and they’re all powerful tools for writing expressive, concise, idiomatic code. If you’re not familiar with them, you’re missing out on one of Perl’s secret superpowers.
In this post, I’ll walk through all the main types of slices in Perl — from the basics to the modern conveniences added in recent versions — using a consistent, real-world-ish example. Whether you’re new to slices or already slinging %hash{...} like a pro, I hope you’ll find something useful here.
The Scenario
Let’s imagine you’re writing code to manage employees in a company. You’ve got an array of employee names and a hash of employee details.
my @employees = qw(alice bob carol dave eve); my %details = ( alice => 'Engineering', bob => 'Marketing', carol => 'HR', dave => 'Engineering', eve => 'Sales', );
We’ll use these throughout to demonstrate each kind of slice.
1. List Slices
List slices are slices from a literal list. They let you pick multiple values from a list in a single operation:
my @subset = (qw(alice bob carol dave eve))[1, 3];
# @subset = ('bob', 'dave')You can also destructure directly:
my ($employee1, $employee2) = (qw(alice bob carol))[0, 2]; # $employee1 = 'alice', $employee2 = 'carol'
Simple, readable, and no loop required.
2. Array Slices
Array slices are just like list slices, but from an array variable:
my @subset = @employees[0, 2, 4];
# @subset = ('alice', 'carol', 'eve')You can also assign into an array slice to update multiple elements:
@employees[1, 3] = ('beatrice', 'daniel');
# @employees = ('alice', 'beatrice', 'carol', 'daniel', 'eve')Handy for bulk updates without writing explicit loops.
3. Hash Slices
This is where some people start to raise eyebrows — but hash slices are perfectly valid Perl and incredibly useful.
Let’s grab departments for a few employees:
my @departments = @details{'alice', 'carol', 'eve'};
# @departments = ('Engineering', 'HR', 'Sales')The @ sigil here indicates that we’re asking for a list of values, even though %details is a hash.
You can assign into a hash slice just as easily:
@details{'bob', 'carol'} = ('Support', 'Legal');This kind of bulk update is especially useful when processing structured data or transforming API responses.
4. Index/Value Array Slices (Perl 5.20+)
Starting in Perl 5.20, you can use %array[...] to return index/value pairs — a very elegant way to extract and preserve positions in a single step.
my @indexed = %employees[1, 3]; # @indexed = (1 => 'bob', 3 => 'dave')
You get a flat list of index/value pairs. This is particularly helpful when mapping or reordering data based on array positions.
You can even delete from an array this way:
my @removed = delete %employees[0, 4]; # @removed = (0 => 'alice', 4 => 'eve')
And afterwards you’ll have this:
# @employees = (undef, 'bob', 'carol', 'dave', undef)
5. Key/Value Hash Slices (Perl 5.20+)
The final type of slice — also added in Perl 5.20 — is the %hash{...} key/value slice. This returns a flat list of key/value pairs, perfect for passing to functions that expect key/value lists.
my @kv = %details{'alice', 'dave'};
# @kv = ('alice', 'Engineering', 'dave', 'Engineering')You can construct a new hash from this easily:
my %engineering = (%details{'alice', 'dave'});This avoids intermediate looping and makes your code clear and declarative.
Summary: Five Flavours of Slice
| Type | Syntax | Returns | Added in |
|---|---|---|---|
| List slice | (list)[@indices] |
Values | Ancient |
| Array slice | @array[@indices] |
Values | Ancient |
| Hash slice | @hash{@keys} |
Values | Ancient |
| Index/value array slice | %array[@indices] |
Index-value pairs | Perl 5.20 |
| Key/value hash slice | %hash{@keys} |
Key-value pairs | Perl 5.20 |
Final Thoughts
If someone tells you that @hash{...} or %array[...] doesn’t work — they’re either out of date or mistaken. These forms are standard, powerful, and idiomatic Perl.
Slices make your code cleaner, clearer, and more concise. They let you express what you want directly, without boilerplate. And yes — they’re perfectly interview-appropriate.
So next time you’re reaching for a loop to pluck a few values from a hash or an array, pause and ask: could this be a slice?
If the answer’s yes — go ahead and slice away.
The post A Slice of Perl first appeared on Perl Hacks.
Earlier this week, I read a post from someone who failed a job interview because they used a hash slice in some sample code and the interviewer didn’t believe it would work.
That’s not just wrong — it’s a teachable moment. Perl has several kinds of slices, and they’re all powerful tools for writing expressive, concise, idiomatic code. If you’re not familiar with them, you’re missing out on one of Perl’s secret superpowers.
In this post, I’ll walk through all the main types of slices in Perl — from the basics to the modern conveniences added in recent versions — using a consistent, real-world-ish example. Whether you’re new to slices or already slinging %hash{...} like a pro, I hope you’ll find something useful here.
The Scenario
Let’s imagine you’re writing code to manage employees in a company. You’ve got an array of employee names and a hash of employee details.
my @employees = qw(alice bob carol dave eve);
my %details = (
alice => 'Engineering',
bob => 'Marketing',
carol => 'HR',
dave => 'Engineering',
eve => 'Sales',
);
We’ll use these throughout to demonstrate each kind of slice.
1. List Slices
List slices are slices from a literal list. They let you pick multiple values from a list in a single operation:
my @subset = (qw(alice bob carol dave eve))[1, 3];
# @subset = ('bob', 'dave')
You can also destructure directly:
my ($employee1, $employee2) = (qw(alice bob carol))[0, 2];
# $employee1 = 'alice', $employee2 = 'carol'
Simple, readable, and no loop required.
2. Array Slices
Array slices are just like list slices, but from an array variable:
my @subset = @employees[0, 2, 4];
# @subset = ('alice', 'carol', 'eve')
You can also assign into an array slice to update multiple elements:
@employees[1, 3] = ('beatrice', 'daniel');
# @employees = ('alice', 'beatrice', 'carol', 'daniel', 'eve')
Handy for bulk updates without writing explicit loops.
3. Hash Slices
This is where some people start to raise eyebrows — but hash slices are perfectly valid Perl and incredibly useful.
Let’s grab departments for a few employees:
my @departments = @details{'alice', 'carol', 'eve'};
# @departments = ('Engineering', 'HR', 'Sales')
The @ sigil here indicates that we’re asking for a list of values, even though %details is a hash.
You can assign into a hash slice just as easily:
@details{'bob', 'carol'} = ('Support', 'Legal');
This kind of bulk update is especially useful when processing structured data or transforming API responses.
4. Index/Value Array Slices (Perl 5.20+)
Starting in Perl 5.20 , you can use %array[...] to return index/value pairs — a very elegant way to extract and preserve positions in a single step.
my @indexed = %employees[1, 3];
# @indexed = (1 => 'bob', 3 => 'dave')
You get a flat list of index/value pairs. This is particularly helpful when mapping or reordering data based on array positions.
You can even delete from an array this way:
my @removed = delete %employees[0, 4];
# @removed = (0 => 'alice', 4 => 'eve')
And afterwards you’ll have this:
# @employees = (undef, 'bob', 'carol', 'dave', undef)
5. Key/Value Hash Slices (Perl 5.20+)
The final type of slice — also added in Perl 5.20 — is the %hash{...} key/value slice. This returns a flat list of key/value pairs, perfect for passing to functions that expect key/value lists.
my @kv = %details{'alice', 'dave'};
# @kv = ('alice', 'Engineering', 'dave', 'Engineering')
You can construct a new hash from this easily:
my %engineering = (%details{'alice', 'dave'});
This avoids intermediate looping and makes your code clear and declarative.
Summary: Five Flavours of Slice
| Type | Syntax | Returns | Added in |
|---|---|---|---|
| List slice | (list)[@indices] |
Values | Ancient |
| Array slice | @array[@indices] |
Values | Ancient |
| Hash slice | @hash{@keys} |
Values | Ancient |
| Index/value array slice | %array[@indices] |
Index-value pairs | Perl 5.20 |
| Key/value hash slice | %hash{@keys} |
Key-value pairs | Perl 5.20 |
Final Thoughts
If someone tells you that @hash{...} or %array[...] doesn’t work — they’re either out of date or mistaken. These forms are standard, powerful, and idiomatic Perl.
Slices make your code cleaner, clearer, and more concise. They let you express what you want directly, without boilerplate. And yes — they’re perfectly interview-appropriate.
So next time you’re reaching for a loop to pluck a few values from a hash or an array, pause and ask: could this be a slice?
If the answer’s yes — go ahead and slice away.
The post A Slice of Perl first appeared on Perl Hacks.
Back in January, I wrote a blog post about adding JSON-LD to your web pages to make it easier for Google to understand what they were about. The example I used was my ReadABooker site, which encourages people to read more Booker Prize shortlisted novels (and to do so by buying them using my Amazon Associate links).
I’m slightly sad to report that in the five months since I implemented that change, visits to the website have remained pretty much static and I have yet to make my fortune from Amazon kickbacks. But that’s ok, we just use it as an excuse to learn more about SEO and to apply more tweaks to the website.
I’ve been using the most excellent ARefs site to get information about how good the on-page SEO is for many of my sites. Every couple of weeks, ARefs crawls the site and will give me a list of suggestions of things I can improve. And for a long time, I had been putting off dealing with one of the biggest issues – because it seemed so difficult.
The site didn’t have enough text on it. You could get lists of Booker years, authors and books. And, eventually, you’d end up on a book page where, hopefully, you’d be tempted to buy a book. But the book pages were pretty bare – just the title, author, year they were short-listed and an image of the cover. Oh, and the all-important “Buy from Amazon” button. AHrefs was insistent that I needed more text (at least a hundred words) on a page in order for Google to take an interest in it. And given that my database of Booker books included hundreds of books by hundreds of authors, that seemed like a big job to take on.
But, a few days ago, I saw a solution to that problem – I could ask ChatGPT for the text.
I wrote a blog post in April about generating a daily-updating website using ChatGPT. This would be similar, but instead of writing the text directly to a Jekyll website, I’d write it to the database and add it to the templates that generate the website.
Adapting the code was very quick. Here’s the finished version for the book blurbs.
#!/usr/bin/env perl
use strict;
use warnings;
use builtin qw[trim];
use feature 'say';
use OpenAPI::Client::OpenAI;
use Time::Piece;
use Encode qw[encode];
use Booker::Schema;
my $sch = Booker::Schema->get_schema;
my $count = 0;
my $books = $sch->resultset('Book');
while ($count < 20 and my $book = $books->next) {
next if defined $book->blurb;
++$count;
my $blurb = describe_title($book);
$book->update({ blurb => $blurb });
}
sub describe_title {
my ($book) = @_;
my ($title, $author) = ($book->title, $book->author->name);
my $debug = 1;
my $api_key = $ENV{"OPENAI_API_KEY"} or die "OPENAI_API_KEY is not set\n";
my $client = OpenAPI::Client::OpenAI->new;
my $prompt = join " ",
'Produce a 100-200 word description for the book',
"'$title' by $author",
'Do not mention the fact that the book was short-listed for (or won)',
'the Booker Prize';
my $res = $client->createChatCompletion({
body => {
model => 'gpt-4o',
# model => 'gpt-4.1-nano',
messages => [
{ role => 'system', content => 'You are someone who knows a lot about popular literature.' },
{ role => 'user', content => $prompt },
],
temperature => 1.0,
},
});
my $text = $res->res->json->{choices}[0]{message}{content};
$text = encode('UTF-8', $text);
say $text if $debug;
return $text;
}There are a couple of points to note:
- I have DBIC classes to deal with the database interaction, so that’s all really simple. Before running this code, I added new columns to the relevant tables and re-ran my process for generating the DBIC classes
- I put a throttle on the processing, so each run would only update twenty books – I slightly paranoid about using too many requests and annoying OpenAI. That wasn’t a problem at all
- The hardest thing (not that it was very hard at all) was to tweak the prompt to give me exactly what I wanted
I then produced a similar program that did the same thing for authors. It’s similar enough that the next time I need something like this, I’ll spend some time turning it into a generic program.
I then added the new database fields to the book and author templates and re-published the site. You can see the results in, for example, the pages for Salman Rushie and Midnight’s Children.
I had one more slight concern going into this project. I pay for access to the ChatGPT API. I usually have about $10 in my pre-paid account and I really had no idea how much this was going to cost me. I needed have worried. Here’s a graph showing the bump in my API usage on the day I ran the code for all books and authors:
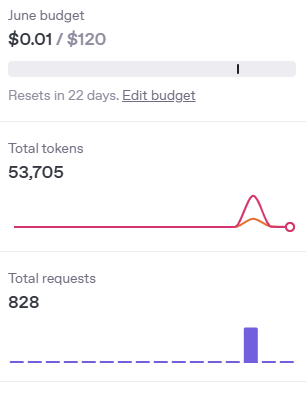
But you can also see that my total costs for the month so far are $0.01!
So, all-in-all, I call that a success and I’ll be using similar techniques to generate content for some other websites.
The post Generating Content with ChatGPT first appeared on Perl Hacks.
Back in January, I wrote a blog post about adding JSON-LD to your web pages to make it easier for Google to understand what they were about. The example I used was my ReadABooker site, which encourages people to read more Booker Prize shortlisted novels (and to do so by buying them using my Amazon Associate links).
I’m slightly sad to report that in the five months since I implemented that change, visits to the website have remained pretty much static and I have yet to make my fortune from Amazon kickbacks. But that’s ok, we just use it as an excuse to learn more about SEO and to apply more tweaks to the website.
I’ve been using the most excellent ARefs site to get information about how good the on-page SEO is for many of my sites. Every couple of weeks, ARefs crawls the site and will give me a list of suggestions of things I can improve. And for a long time, I had been putting off dealing with one of the biggest issues – because it seemed so difficult.
The site didn’t have enough text on it. You could get lists of Booker years, authors and books. And, eventually, you’d end up on a book page where, hopefully, you’d be tempted to buy a book. But the book pages were pretty bare – just the title, author, year they were short-listed and an image of the cover. Oh, and the all-important “Buy from Amazon” button. AHrefs was insistent that I needed more text (at least a hundred words) on a page in order for Google to take an interest in it. And given that my database of Booker books included hundreds of books by hundreds of authors, that seemed like a big job to take on.
But, a few days ago, I saw a solution to that problem – I could ask ChatGPT for the text.
I wrote a blog post in April about generating a daily-updating website using ChatGPT. This would be similar, but instead of writing the text directly to a Jekyll website, I’d write it to the database and add it to the templates that generate the website.
Adapting the code was very quick. Here’s the finished version for the book blurbs.
#!/usr/bin/env perl
use strict;
use warnings;
use builtin qw[trim];
use feature 'say';
use OpenAPI::Client::OpenAI;
use Time::Piece;
use Encode qw[encode];
use Booker::Schema;
my $sch = Booker::Schema->get_schema;
my $count = 0;
my $books = $sch->resultset('Book');
while ($count < 20 and my $book = $books->next) {
next if defined $book->blurb;
++$count;
my $blurb = describe_title($book);
$book->update({ blurb => $blurb });
}
sub describe_title {
my ($book) = @_;
my ($title, $author) = ($book->title, $book->author->name);
my $debug = 1;
my $api_key = $ENV{"OPENAI_API_KEY"} or die "OPENAI_API_KEY is not set\n";
my $client = OpenAPI::Client::OpenAI->new;
my $prompt = join " ",
'Produce a 100-200 word description for the book',
"'$title' by $author",
'Do not mention the fact that the book was short-listed for (or won)',
'the Booker Prize';
my $res = $client->createChatCompletion({
body => {
model => 'gpt-4o',
# model => 'gpt-4.1-nano',
messages => [
{ role => 'system', content => 'You are someone who knows a lot about popular literature.' },
{ role => 'user', content => $prompt },
],
temperature => 1.0,
},
});
my $text = $res->res->json->{choices}[0]{message}{content};
$text = encode('UTF-8', $text);
say $text if $debug;
return $text;
}
There are a couple of points to note:
- I have DBIC classes to deal with the database interaction, so that’s all really simple. Before running this code, I added new columns to the relevant tables and re-ran my process for generating the DBIC classes
- I put a throttle on the processing, so each run would only update twenty books – I slightly paranoid about using too many requests and annoying OpenAI. That wasn’t a problem at all
- The hardest thing (not that it was very hard at all) was to tweak the prompt to give me exactly what I wanted
I then produced a similar program that did the same thing for authors. It’s similar enough that the next time I need something like this, I’ll spend some time turning it into a generic program.
I then added the new database fields to the book and author templates and re-published the site. You can see the results in, for example, the pages for Salman Rushie and Midnight’s Children.
I had one more slight concern going into this project. I pay for access to the ChatGPT API. I usually have about $10 in my pre-paid account and I really had no idea how much this was going to cost me. I needed have worried. Here’s a graph showing the bump in my API usage on the day I ran the code for all books and authors:
But you can also see that my total costs for the month so far are $0.01!
So, all-in-all, I call that a success and I’ll be using similar techniques to generate content for some other websites.
The post Generating Content with ChatGPT first appeared on Perl Hacks.
Last summer, I wrote a couple of posts about my lightweight, roll-your-own approach to deploying PSGI (Dancer) web apps:
In those posts, I described how I avoided heavyweight deployment tools by writing a small, custom Perl script (app_service) to start and manage them. It was minimal, transparent, and easy to replicate.
It also wasn’t great.
What Changed?
The system mostly worked, but it had a number of growing pains:
- It didn’t integrate with the host operating system in a meaningful way.
- Services weren’t resilient — no automatic restarts on failure.
- There was no logging consolidation, no dependency management (e.g., waiting for the network), and no visibility in tools like
systemctl. - If a service crashed, I’d usually find out via
curl, notjournalctl.
As I started running more apps, this ad-hoc approach became harder to justify. It was time to grow up.
Enter psgi-systemd-deploy
So today (with some help from ChatGPT) I wrote psgi-systemd-deploy — a simple, declarative deployment tool for PSGI apps that integrates directly with systemd. It generates .service files for your apps from environment-specific config and handles all the fiddly bits (paths, ports, logging, restart policies, etc.) with minimal fuss.
Key benefits:
-
- Declarative config via
.deploy.env - Optional
.envfile support for application-specific settings - Environment-aware templating using
envsubst - No lock-in — it just writes
systemdunits you can inspect and manage yourself
- Declarative config via
- Safe — supports a
--dry-runmode so you can preview changes before deploying - Convenient — includes a
run_allhelper script for managing all your deployed apps with one command
A Real-World Example
You may know about my Line of Succession web site (introductory talk). This is one of the Dancer apps I’ve been talking about. To deploy it, I wrote a .deploy.env file that looks like this:
WEBAPP_SERVICE_NAME=succession WEBAPP_DESC="British Line of Succession" WEBAPP_WORKDIR=/opt/succession WEBAPP_USER=succession WEBAPP_GROUP=psacln WEBAPP_PORT=2222 WEBAPP_WORKER_COUNT=5 WEBAPP_APP_PRELOAD=1
And optionally a .env file for app-specific settings (e.g., database credentials). Then I run:
$ /path/to/psgi-systemd-deploy/deploy.sh
And that’s it. The app is now a first-class systemd service, automatically started on boot and restartable with systemctl.
Managing All Your Apps with run_all
Once you’ve deployed several PSGI apps using psgi-systemd-deploy, you’ll probably want an easy way to manage them all at once. That’s where the run_all script comes in.
It’s a simple but powerful wrapper around systemctl that automatically discovers all deployed services by scanning for .deploy.env files. That means no need to hard-code service names or paths — it just works, based on the configuration you’ve already provided.
Here’s how you might use it:
# Restart all PSGI apps $ run_all restart # Show current status $ run_all status # Stop them all (e.g., for maintenance) $ run_all stop
And if you want machine-readable output for scripting or monitoring, there’s a --json flag:
$ run_all --json is-active | jq .
[
{
"service": "succession.service",
"action": "is-active",
"status": 0,
"output": "active"
},
{
"service": "klortho.service",
"action": "is-active",
"status": 0,
"output": "active"
}
]Under the hood, run_all uses the same environment-driven model as the rest of the system — no surprises, no additional config files. It’s just a lightweight helper that understands your layout and automates the boring bits.
It’s not a replacement for systemctl, but it makes common tasks across many services far more convenient — especially during development, deployment, or server reboots.
A Clean Break
The goal of psgi-systemd-deploy isn’t to replace Docker, K8s, or full-featured PaaS systems. It’s for the rest of us — folks running VPSes or bare-metal boxes where PSGI apps just need to run reliably and predictably under the OS’s own tools.
If you’ve been rolling your own init scripts, cron jobs, or nohup-based hacks, give it a look. It’s clean, simple, and reliable — and a solid step up from duct tape.

The post Deploying Dancer Apps – The Next Generation first appeared on Perl Hacks.
Last summer, I wrote a couple of posts about my lightweight, roll-your-own approach to deploying PSGI (Dancer) web apps:
In those posts, I described how I avoided heavyweight deployment tools by writing a small, custom Perl script (app_service) to start and manage them. It was minimal, transparent, and easy to replicate.
It also wasn’t great.
What Changed?
The system mostly worked, but it had a number of growing pains:
- It didn’t integrate with the host operating system in a meaningful way.
- Services weren’t resilient — no automatic restarts on failure.
- There was no logging consolidation, no dependency management (e.g., waiting for the network), and no visibility in tools like
systemctl. - If a service crashed, I’d usually find out via
curl, notjournalctl.
As I started running more apps, this ad-hoc approach became harder to justify. It was time to grow up.
Enter psgi-systemd-deploy
So today (with some help from ChatGPT) I wrote psgi-systemd-deploy — a simple, declarative deployment tool for PSGI apps that integrates directly with systemd. It generates .service files for your apps from environment-specific config and handles all the fiddly bits (paths, ports, logging, restart policies, etc.) with minimal fuss.
Key benefits:
-
Declarative config via
.deploy.env -
Optional
.envfile support for application-specific settings -
Environment-aware templating using
envsubst -
No lock-in — it just writes
systemdunits you can inspect and manage yourself
-
Declarative config via
Safe — supports a
--dry-runmode so you can preview changes before deployingConvenient — includes a
run_allhelper script for managing all your deployed apps with one command
A Real-World Example
You may know about my Line of Succession web site (introductory talk). This is one of the Dancer apps I’ve been talking about. To deploy it, I wrote a .deploy.env file that looks like this:
WEBAPP_SERVICE_NAME=succession
WEBAPP_DESC="British Line of Succession"
WEBAPP_WORKDIR=/opt/succession
WEBAPP_USER=succession
WEBAPP_GROUP=psacln
WEBAPP_PORT=2222
WEBAPP_WORKER_COUNT=5
WEBAPP_APP_PRELOAD=1
And optionally a .env file for app-specific settings (e.g., database credentials). Then I run:
$ /path/to/psgi-systemd-deploy/deploy.sh
And that’s it. The app is now a first-class systemd service, automatically started on boot and restartable with systemctl.
Managing All Your Apps with run_all
Once you’ve deployed several PSGI apps using psgi-systemd-deploy, you’ll probably want an easy way to manage them all at once. That’s where the run_all script comes in.
It’s a simple but powerful wrapper around systemctl that automatically discovers all deployed services by scanning for .deploy.env files. That means no need to hard-code service names or paths — it just works, based on the configuration you’ve already provided.
Here’s how you might use it:
# Restart all PSGI apps
$ run_all restart
# Show current status
$ run_all status
# Stop them all (e.g., for maintenance)
$ run_all stop
And if you want machine-readable output for scripting or monitoring, there’s a --json flag:
$ run_all --json is-active | jq .
[
{
"service": "succession.service",
"action": "is-active",
"status": 0,
"output": "active"
},
{
"service": "klortho.service",
"action": "is-active",
"status": 0,
"output": "active"
}
]
Under the hood, run_all uses the same environment-driven model as the rest of the system — no surprises, no additional config files. It’s just a lightweight helper that understands your layout and automates the boring bits.
It’s not a replacement for systemctl, but it makes common tasks across many services far more convenient — especially during development, deployment, or server reboots.
A Clean Break
The goal of psgi-systemd-deploy isn’t to replace Docker, K8s, or full-featured PaaS systems. It’s for the rest of us — folks running VPSes or bare-metal boxes where PSGI apps just need to run reliably and predictably under the OS’s own tools.
If you’ve been rolling your own init scripts, cron jobs, or nohup-based hacks, give it a look. It’s clean, simple, and reliable — and a solid step up from duct tape.

The post Deploying Dancer Apps – The Next Generation first appeared on Perl Hacks.
Like most developers, I have a mental folder labelled “useful little tools I’ll probably never build.” Small utilities, quality-of-life scripts, automations — they’d save time, but not enough to justify the overhead of building them. So they stay stuck in limbo.
That changed when I started using AI as a regular part of my development workflow.
Now, when I hit one of those recurring minor annoyances — something just frictiony enough to slow me down — I open a ChatGPT tab. Twenty minutes later, I usually have a working solution. Not always perfect, but almost always 90% of the way there. And once that initial burst of momentum is going, finishing it off is easy.
It’s not quite mind-reading. But it is like having a superpowered pair programmer on tap.
The Problem
Obviously, I do a lot of Perl development. When working on a Perl project, it’s common to have one or more lib/ directories in the repo that contain the project’s modules. To run test scripts or local tools, I often need to set the PERL5LIB environment variable so that Perl can find those modules.
But I’ve got a lot of Perl projects — often nested in folders like ~/git, and sometimes with extra lib/ directories for testing or shared code. And I switch between them frequently. Typing:
export PERL5LIB=lib
…over and over gets boring fast. And worse, if you forget to do it, your test script breaks with a misleading “Can’t locate Foo/Bar.pm” error.
What I wanted was this:
-
Every time I
cdinto a directory, if there are any validlib/subdirectories beneath it, setPERL5LIBautomatically. -
Only include
lib/dirs that actually contain.pmfiles. -
Skip junk like
.vscode,blib, and old release folders likeMyModule-1.23/. -
Don’t scan the entire world if I
cd ~/git, which contains hundreds of repos. -
Show me what it’s doing, and let me test it in dry-run mode.
The Solution
With ChatGPT, I built a drop-in Bash function in about half an hour that does exactly that. It’s now saved as perl5lib_auto.sh, and it:
-
Wraps
cd()to trigger a scan after every directory change -
Finds all qualifying
lib/directories beneath the current directory -
Filters them using simple rules:
-
Must contain
.pmfiles -
Must not be under
.vscode/,.blib/, or versioned build folders
-
-
Excludes specific top-level directories (like
~/git) by default -
Lets you configure everything via environment variables
-
Offers
verbose,dry-run, andforcemodes -
Can append to or overwrite your existing
PERL5LIB
You drop it in your ~/.bashrc (or wherever you like), and your shell just becomes a little bit smarter.
Usage Example
source ~/bin/perl5lib_auto.sh cd ~/code/MyModule # => PERL5LIB set to: /home/user/code/MyModule/lib PERL5LIB_VERBOSE=1 cd ~/code/AnotherApp # => [PERL5LIB] Found 2 eligible lib dir(s): # => /home/user/code/AnotherApp/lib # => /home/user/code/AnotherApp/t/lib # => PERL5LIB set to: /home/user/code/AnotherApp/lib:/home/user/code/AnotherApp/t/lib
You can also set environment variables to customise behaviour:
export PERL5LIB_EXCLUDE_DIRS="$HOME/git:$HOME/legacy" export PERL5LIB_EXCLUDE_PATTERNS=".vscode:blib" export PERL5LIB_LIB_CAP=5 export PERL5LIB_APPEND=1
Or simulate what it would do:
PERL5LIB_DRYRUN=1 cd ~/code/BigProject
Try It Yourself
The full script is available on GitHub:
 https://github.com/davorg/perl5lib_auto
https://github.com/davorg/perl5lib_auto
I’d love to hear how you use it — or how you’d improve it. Feel free to:
-
 Star the repo
Star the repo -
 Open issues for suggestions or bugs
Open issues for suggestions or bugs -
 Send pull requests with fixes, improvements, or completely new ideas
Send pull requests with fixes, improvements, or completely new ideas
It’s a small tool, but it’s already saved me a surprising amount of friction. If you’re a Perl hacker who jumps between projects regularly, give it a try — and maybe give AI co-coding a try too while you’re at it.
What useful little utilities have you written with help from an AI pair-programmer?
The post Turning AI into a Developer Superpower: The PERL5LIB Auto-Setter first appeared on Perl Hacks.
Like most developers, I have a mental folder labelled “useful little tools I’ll probably never build.” Small utilities, quality-of-life scripts, automations — they’d save time, but not enough to justify the overhead of building them. So they stay stuck in limbo.
That changed when I started using AI as a regular part of my development workflow.
Now, when I hit one of those recurring minor annoyances — something just frictiony enough to slow me down — I open a ChatGPT tab. Twenty minutes later, I usually have a working solution. Not always perfect, but almost always 90% of the way there. And once that initial burst of momentum is going, finishing it off is easy.
It’s not quite mind-reading. But it is like having a superpowered pair programmer on tap.
The Problem
Obviously, I do a lot of Perl development. When working on a Perl project, it’s common to have one or more lib/ directories in the repo that contain the project’s modules. To run test scripts or local tools, I often need to set the PERL5LIB environment variable so that Perl can find those modules.
But I’ve got a lot of Perl projects — often nested in folders like ~/git, and sometimes with extra lib/ directories for testing or shared code. And I switch between them frequently. Typing:
export PERL5LIB=lib
…over and over gets boring fast. And worse, if you forget to do it, your test script breaks with a misleading “Can’t locate Foo/Bar.pm” error.
What I wanted was this:
Every time I
cdinto a directory, if there are any validlib/subdirectories beneath it, setPERL5LIBautomatically.Only include
lib/dirs that actually contain.pmfiles.Skip junk like
.vscode,blib, and old release folders likeMyModule-1.23/.Don’t scan the entire world if I
cd ~/git, which contains hundreds of repos.Show me what it’s doing, and let me test it in dry-run mode.
The Solution
With ChatGPT, I built a drop-in Bash function in about half an hour that does exactly that. It’s now saved as perl5lib_auto.sh, and it:
Wraps
cd()to trigger a scan after every directory changeFinds all qualifying
lib/directories beneath the current directoryFilters them using simple rules:
Excludes specific top-level directories (like
~/git) by defaultLets you configure everything via environment variables
Offers
verbose,dry-run, andforcemodesCan append to or overwrite your existing
PERL5LIB
You drop it in your ~/.bashrc (or wherever you like), and your shell just becomes a little bit smarter.
Usage Example
source ~/bin/perl5lib_auto.sh
cd ~/code/MyModule
# => PERL5LIB set to: /home/user/code/MyModule/lib
PERL5LIB_VERBOSE=1 cd ~/code/AnotherApp
# => [PERL5LIB] Found 2 eligible lib dir(s):
# => /home/user/code/AnotherApp/lib
# => /home/user/code/AnotherApp/t/lib
# => PERL5LIB set to: /home/user/code/AnotherApp/lib:/home/user/code/AnotherApp/t/lib
You can also set environment variables to customise behaviour:
export PERL5LIB_EXCLUDE_DIRS="$HOME/git:$HOME/legacy"
export PERL5LIB_EXCLUDE_PATTERNS=".vscode:blib"
export PERL5LIB_LIB_CAP=5
export PERL5LIB_APPEND=1
Or simulate what it would do:
PERL5LIB_DRYRUN=1 cd ~/code/BigProject
Try It Yourself
The full script is available on GitHub:
I’d love to hear how you use it — or how you’d improve it. Feel free to:
⭐ Star the repo
🐛 Open issues for suggestions or bugs
🔀 Send pull requests with fixes, improvements, or completely new ideas
It’s a small tool, but it’s already saved me a surprising amount of friction. If you’re a Perl hacker who jumps between projects regularly, give it a try — and maybe give AI co-coding a try too while you’re at it.
What useful little utilities have you written with help from an AI pair-programmer?
The post Turning AI into a Developer Superpower: The PERL5LIB Auto-Setter first appeared on Perl Hacks.

author: Daniel McClellan
name: David
average rating: 4.44
book published:
rating: 0
read at:
date added: 2025/05/06
shelves: currently-reading
review:
Building a website in a day — with help from ChatGPT

A few days ago, I looked at an unused domain I owned — balham.org — and thought: “There must be a way to make this useful… and maybe even make it pay for itself.”
So I set myself a challenge: one day to build something genuinely useful. A site that served a real audience (people in and around Balham), that was fun to build, and maybe could be turned into a small revenue stream.
It was also a great excuse to get properly stuck into Jekyll and the Minimal Mistakes theme — both of which I’d dabbled with before, but never used in anger. And, crucially, I wasn’t working alone: I had ChatGPT as a development assistant, sounding board, researcher, and occasional bug-hunter.
The Idea
Balham is a reasonably affluent, busy part of south west London. It’s full of restaurants, cafés, gyms, independent shops, and people looking for things to do. It also has a surprisingly rich local history — from Victorian grandeur to Blitz-era tragedy.
I figured the site could be structured around three main pillars:
Throw in a curated homepage and maybe a blog later, and I had the bones of a useful site. The kind of thing that people would find via Google or get sent a link to by a friend.
The Stack
I wanted something static, fast, and easy to deploy. My toolchain ended up being:
- Jekyll for the site generator
- Minimal Mistakes as the theme
- GitHub Pages for hosting
- Custom YAML data files for businesses and events
- ChatGPT for everything from content generation to Liquid loops
The site is 100% static, with no backend, no databases, no CMS. It builds automatically on GitHub push, and is entirely hosted via GitHub Pages.
Step by Step: Building It
I gave us about six solid hours to build something real. Here’s what we did (“we” meaning me + ChatGPT):
1. Domain Setup and Scaffolding
The domain was already pointed at GitHub Pages, and I had a basic “Hello World” site in place. We cleared that out, set up a fresh Jekyll repo, and added a _config.yml that pointed at the Minimal Mistakes remote theme. No cloning or submodules.
2. Basic Site Structure
We decided to create four main pages:
We used the layout: single layout provided by Minimal Mistakes, and created custom permalinks so URLs were clean and extension-free.
3. The Business Directory
This was built from scratch using a YAML data file (_data/businesses.yml). ChatGPT gathered an initial list of 20 local businesses (restaurants, shops, pubs, etc.), checked their status, and added details like name, category, address, website, and a short description.
In the template, we looped over the list, rendered sections with conditional logic (e.g., don’t output the website link if it’s empty), and added anchor IDs to each entry so we could link to them directly from the homepage.
4. The Events Page
Built exactly the same way, but using _data/events.yml. To keep things realistic, we seeded a small number of example events and included a note inviting people to email us with new submissions.
5. Featured Listings
We wanted the homepage to show a curated set of businesses and events. So we created a third data file, _data/featured.yml, which just listed the names of the featured entries. Then in the homepage template, we used where and slugify to match names and pull in the full record from businesses.yml or events.yml. Super DRY.
6. Map and Media
We added a map of Balham as a hero image, styled responsively. Later we created a .responsive-inline-image class to embed supporting images on the history page without overwhelming the layout.
7. History Section with Real Archival Images
This turned out to be one of the most satisfying parts. We wrote five paragraphs covering key moments in Balham’s development — Victorian expansion, Du Cane Court, The Priory, the Blitz, and modern growth.
Then we sourced five CC-licensed or public domain images (from Wikimedia Commons and Geograph) to match each paragraph. Each was wrapped in a <figure> with proper attribution and a consistent CSS class. The result feels polished and informative.
8. Metadata, SEO, and Polish
We went through all the basics:
- Custom title and description in front matter for each page
- Open Graph tags and Twitter cards via site config
- A branded favicon using RealFaviconGenerator
- Added robots.txt, sitemap.xml, and a hand-crafted humans.txt
- Clean URLs, no .html extensions
- Anchored IDs for deep linking
9. Analytics and Search Console
We added GA4 tracking using Minimal Mistakes’ built-in support, and verified the domain with Google Search Console. A sitemap was submitted, and indexing kicked in within minutes.
10. Accessibility and Performance
We ran Lighthouse and WAVE tests. Accessibility came out at 100%. Performance dipped slightly due to Google Fonts and image size, but we did our best to optimise without sacrificing aesthetics.
11. Footer CTA
We added a site-wide footer call-to-action inviting people to email us with suggestions for businesses or events. This makes the site feel alive and participatory, even without a backend form.
What Worked Well
- ChatGPT as co-pilot: I could ask it for help with Liquid templates, CSS, content rewrites, and even bug-hunting. It let me move fast without getting bogged down in docs.
- Minimal Mistakes: It really is an excellent theme. Clean, accessible, flexible.
- Data-driven content: Keeping everything in YAML meant templates stayed simple, and the whole site is easy to update.
- Staying focused: We didn’t try to do everything. Four pages, one day, good polish.
What’s Next?
- Add category filtering to the directory
- Improve the OG/social card image
- Add structured JSON-LD for individual events and businesses
- Explore monetisation: affiliate links, sponsored listings, local partnerships
- Start some blog posts or “best of Balham” roundups
Final Thoughts
This started as a fun experiment: could I monetise an unused domain and finally learn Jekyll properly?
What I ended up with is a genuinely useful local resource — one that looks good, loads quickly, and has room to grow.
If you’re sitting on an unused domain, and you’ve got a free day and a chatbot at your side — you might be surprised what you can build.
Oh, and one final thing — obviously you can also get ChatGPT to write a blog post talking about the project :-)
Originally published at https://blog.dave.org.uk on March 23, 2025.
A few days ago, I looked at an unused domain I owned — balham.org — and thought: “There must be a way to make this useful… and maybe even make it pay for itself.”
So I set myself a challenge: one day to build something genuinely useful. A site that served a real audience (people in and around Balham), that was fun to build, and maybe could be turned into a small revenue stream.
It was also a great excuse to get properly stuck into Jekyll and the Minimal Mistakes theme — both of which I’d dabbled with before, but never used in anger. And, crucially, I wasn’t working alone: I had ChatGPT as a development assistant, sounding board, researcher, and occasional bug-hunter.
The Idea
Balham is a reasonably affluent, busy part of south west London. It’s full of restaurants, cafés, gyms, independent shops, and people looking for things to do. It also has a surprisingly rich local history — from Victorian grandeur to Blitz-era tragedy.
I figured the site could be structured around three main pillars:
- A directory of local businesses
- A list of upcoming events
- A local history section
Throw in a curated homepage and maybe a blog later, and I had the bones of a useful site. The kind of thing that people would find via Google or get sent a link to by a friend.
The Stack
I wanted something static, fast, and easy to deploy. My toolchain ended up being:
- Jekyll for the site generator
- Minimal Mistakes as the theme
- GitHub Pages for hosting
- Custom YAML data files for businesses and events
- ChatGPT for everything from content generation to Liquid loops
The site is 100% static, with no backend, no databases, no CMS. It builds automatically on GitHub push, and is entirely hosted via GitHub Pages.
Step by Step: Building It
I gave us about six solid hours to build something real. Here’s what we did (“we” meaning me + ChatGPT):
1. Domain Setup and Scaffolding
The domain was already pointed at GitHub Pages, and I had a basic “Hello World” site in place. We cleared that out, set up a fresh Jekyll repo, and added a _config.yml that pointed at the Minimal Mistakes remote theme. No cloning or submodules.
2. Basic Site Structure
We decided to create four main pages:
- Homepage (
index.md) - Directory (
directory/index.md) - Events (
events/index.md) - History (
history/index.md)
We used the layout: single layout provided by Minimal Mistakes, and created custom permalinks so URLs were clean and extension-free.
3. The Business Directory
This was built from scratch using a YAML data file (_data/businesses.yml). ChatGPT gathered an initial list of 20 local businesses (restaurants, shops, pubs, etc.), checked their status, and added details like name, category, address, website, and a short description.
In the template, we looped over the list, rendered sections with conditional logic (e.g., don’t output the website link if it’s empty), and added anchor IDs to each entry so we could link to them directly from the homepage.
4. The Events Page
Built exactly the same way, but using _data/events.yml. To keep things realistic, we seeded a small number of example events and included a note inviting people to email us with new submissions.
5. Featured Listings
We wanted the homepage to show a curated set of businesses and events. So we created a third data file, _data/featured.yml, which just listed the names of the featured entries. Then in the homepage template, we used where and slugify to match names and pull in the full record from businesses.yml or events.yml. Super DRY.
6. Map and Media
We added a map of Balham as a hero image, styled responsively. Later we created a .responsive-inline-image class to embed supporting images on the history page without overwhelming the layout.
7. History Section with Real Archival Images
This turned out to be one of the most satisfying parts. We wrote five paragraphs covering key moments in Balham’s development — Victorian expansion, Du Cane Court, The Priory, the Blitz, and modern growth.
Then we sourced five CC-licensed or public domain images (from Wikimedia Commons and Geograph) to match each paragraph. Each was wrapped in a <figure> with proper attribution and a consistent CSS class. The result feels polished and informative.
8. Metadata, SEO, and Polish
We went through all the basics:
- Custom
titleanddescriptionin front matter for each page - Open Graph tags and Twitter cards via site config
- A branded favicon using RealFaviconGenerator
- Added
robots.txt,sitemap.xml, and a hand-craftedhumans.txt - Clean URLs, no
.htmlextensions - Anchored IDs for deep linking
9. Analytics and Search Console
We added GA4 tracking using Minimal Mistakes’ built-in support, and verified the domain with Google Search Console. A sitemap was submitted, and indexing kicked in within minutes.
10. Accessibility and Performance
We ran Lighthouse and WAVE tests. Accessibility came out at 100%. Performance dipped slightly due to Google Fonts and image size, but we did our best to optimise without sacrificing aesthetics.
11. Footer CTA
We added a site-wide footer call-to-action inviting people to email us with suggestions for businesses or events. This makes the site feel alive and participatory, even without a backend form.
What Worked Well
- ChatGPT as co-pilot: I could ask it for help with Liquid templates, CSS, content rewrites, and even bug-hunting. It let me move fast without getting bogged down in docs.
- Minimal Mistakes: It really is an excellent theme. Clean, accessible, flexible.
- Data-driven content: Keeping everything in YAML meant templates stayed simple, and the whole site is easy to update.
- Staying focused: We didn’t try to do everything. Four pages, one day, good polish.
What’s Next?
- Add category filtering to the directory
- Improve the OG/social card image
- Add structured JSON-LD for individual events and businesses
- Explore monetisation: affiliate links, sponsored listings, local partnerships
- Start some blog posts or “best of Balham” roundups
Final Thoughts
This started as a fun experiment: could I monetise an unused domain and finally learn Jekyll properly?
What I ended up with is a genuinely useful local resource — one that looks good, loads quickly, and has room to grow.
If you’re sitting on an unused domain, and you’ve got a free day and a chatbot at your side — you might be surprised what you can build.
Oh, and one final thing – obviously you can also get ChatGPT to write a blog post talking about the project :-)
The post Building a website in a day — with help from ChatGPT appeared first on Davblog.

I built and launched a new website yesterday. It wasn’t what I planned to do, but the idea popped into my head while I was drinking my morning coffee on Clapham Common and it seemed to be the kind of thing I could complete in a day — so I decided to put my original plans on hold and built it instead.
The website is aimed at small business owners who think they need a website (or want to update their existing one) but who know next to nothing about web development and can easily fall prey to the many cowboy website companies that seem to dominate the “making websites for small companies” section of our industries. The site is structured around a number of questions you can ask a potential website builder to try and weed out the dodgier elements.
I’m not really in that sector of our industry. But while writing the content for that site, it occurred to me that some people might be interested in the tools I use to build sites like this.
Content
I generally build websites about topics that I’m interested in and, therefore, know a fair bit about. But I probably don’t know everything about these subjects. So I’ll certainly brainstorm some ideas with ChatGPT. And, once I’ve written something, I’ll usually run it through ChatGPT again to proofread it. I consider myself a pretty good writer, but it’s embarrassing how often ChatGPT catches obvious errors.
I’ve used DALL-E (via ChatGPT) for a lot of image generation. This weekend, I subscribed to Midjourney because I heard it was better at generating images that include text. So far, that seems to be accurate.
Technology
I don’t write much raw HTML these days. I’ll generally write in Markdown and use a static site generator to turn that into a real website. This weekend I took the easy route and used Jekyll with the Minimal Mistakes theme. Honestly, I don’t love Jekyll, but it integrates well with GitHub Pages and I can usually get it to do what I want — with a combination of help from ChatGPT and reading the source code. I’m (slowly) building my own Static Site Generator ( Aphra) in Perl. But, to be honest, I find that when I use it I can easily get distracted by adding new features rather than getting the site built.
As I’ve hinted at, if I’m building a static site (and, it’s surprising how often that’s the case), it will be hosted on GitHub Pages. It’s not really aimed at end-users, but I know to you use it pretty well now. This weekend, I used the default mechanism that regenerates the site (using Jekyll) on every commit. But if I’m using Aphra or a custom site generator, I know I can use GitHub Actions to build and deploy the site.
If I’m writing actual HTML, then I’m old-skool enough to still use Bootstrap for CSS. There’s probably something better out there now, but I haven’t tried to work out what it is (feel free to let me know in the comments).
For a long while, I used jQuery to add Javascript to my pages — until someone was kind enough to tell me that vanilla Javascript had mostly caught up and jQuery was no longer necessary. I understand Javascript. And with help from GitHub Copilot, I can usually get it doing what I want pretty quickly.
SEO
Many years ago, I spent a couple of years working in the SEO group at Zoopla. So, now, I can’t think about building a website without considering SEO.
I quickly lose interest in the content side of SEO. Figuring out what my keywords are and making sure they’re scattered through the content at the correct frequency, feels like it stifles my writing (maybe that’s an area where ChatGPT can help) but I enjoy Technical SEO. So I like to make sure that all of my pages contain the correct structured data (usually JSON-LD). I also like to ensure my sites all have useful OpenGraph headers. This isn’t really SEO, I guess, but these headers control what people see when they share content on social media. So by making that as attractive as possible (a useful title and description, an attractive image) it encourages more sharing, which increases your site’s visibility and, in around about way, improves SEO.
I like to register all of my sites with Ahrefs — they will crawl my sites periodically and send me a long list of SEO improvements I can make.
Monitoring
I add Google Analytics to all of my sites. That’s still the best way to find out how popular your site it and where your traffic is coming from. I used to be quite proficient with Universal Analytics, but I must admit I haven’t fully got the hang of Google Analytics 4 yet-so I’m probably only scratching the surface of what it can do.
I also register all of my sites with Google Search Console. That shows me information about how my site appears in the Google Search Index. I also link that to Google Analytics — so GA also knows what searches brought people to my sites.
Conclusion
I think that covers everything-though I’ve probably forgotten something. It might sound like a lot, but once you get into a rhythm, adding these extra touches doesn’t take long. And the additional insights you gain make it well worth the effort.
If you’ve built a website recently, I’d love to hear about your approach. What tools and techniques do you swear by? Are there any must-have features or best practices I’ve overlooked? Drop a comment below or get in touch-I’m always keen to learn new tricks and refine my process. And if you’re a small business owner looking for guidance on choosing a web developer, check out my new site-it might just save you from a costly mistake!
Originally published at https://blog.dave.org.uk on March 16, 2025.
I built and launched a new website yesterday. It wasn’t what I planned to do, but the idea popped into my head while I was drinking my morning coffee on Clapham Common and it seemed to be the kind of thing I could complete in a day – so I decided to put my original plans on hold and built it instead.
The website is aimed at small business owners who think they need a website (or want to update their existing one) but who know next to nothing about web development and can easily fall prey to the many cowboy website companies that seem to dominate the “making websites for small companies” section of our industries. The site is structured around a number of questions you can ask a potential website builder to try and weed out the dodgier elements.
I’m not really in that sector of our industry. But while writing the content for that site, it occurred to me that some people might be interested in the tools I use to build sites like this.
Content
I generally build websites about topics that I’m interested in and, therefore, know a fair bit about. But I probably don’t know everything about these subjects. So I’ll certainly brainstorm some ideas with ChatGPT. And, once I’ve written something, I’ll usually run it through ChatGPT again to proofread it. I consider myself a pretty good writer, but it’s embarrassing how often ChatGPT catches obvious errors.
I’ve used DALL-E (via ChatGPT) for a lot of image generation. This weekend, I subscribed to Midjourney because I heard it was better at generating images that include text. So far, that seems to be accurate.
Technology
I don’t write much raw HTML these days. I’ll generally write in Markdown and use a static site generator to turn that into a real website. This weekend I took the easy route and used Jekyll with the Minimal Mistakes theme. Honestly, I don’t love Jekyll, but it integrates well with GitHub Pages and I can usually get it to do what I want – with a combination of help from ChatGPT and reading the source code. I’m (slowly) building my own Static Site Generator (Aphra) in Perl. But, to be honest, I find that when I use it I can easily get distracted by adding new features rather than getting the site built.
As I’ve hinted at, if I’m building a static site (and, it’s surprising how often that’s the case), it will be hosted on GitHub Pages. It’s not really aimed at end-users, but I know how to use it pretty well now. This weekend, I used the default mechanism that regenerates the site (using Jekyll) on every commit. But if I’m using Aphra or a custom site generator, I know I can use GitHub Actions to build and deploy the site.
If I’m writing actual HTML, then I’m old-skool enough to still use Bootstrap for CSS. There’s probably something better out there now, but I haven’t tried to work out what it is (feel free to let me know in the comments).
For a long while, I used jQuery to add Javascript to my pages – until someone was kind enough to tell me that vanilla Javascript had mostly caught up and jQuery was no longer necessary. I understand Javascript. And with help from GitHub Copilot, I can usually get it doing what I want pretty quickly.
SEO
Many years ago, I spent a couple of years working in the SEO group at Zoopla. So, now, I can’t think about building a website without considering SEO.
I quickly lose interest in the content side of SEO. Figuring out what my keywords are and making sure they’re scattered through the content at the correct frequency, feels like it stifles my writing (maybe that’s an area where ChatGPT can help) but I enjoy Technical SEO. So I like to make sure that all of my pages contain the correct structured data (usually JSON-LD). I also like to ensure my sites all have useful OpenGraph headers. This isn’t really SEO, I guess, but these headers control what people see when they share content on social media. So by making that as attractive as possible (a useful title and description, an attractive image) it encourages more sharing, which increases your site’s visibility and, in around about way, improves SEO.
I like to register all of my sites with Ahrefs – they will crawl my sites periodically and send me a long list of SEO improvements I can make.
Monitoring
I add Google Analytics to all of my sites. That’s still the best way to find out how popular your site it and where your traffic is coming from. I used to be quite proficient with Universal Analytics, but I must admit I haven’t fully got the hang of Google Analytics 4 yet—so I’m probably only scratching the surface of what it can do.
I also register all of my sites with Google Search Console. That shows me information about how my site appears in the Google Search Index. I also link that to Google Analytics – so GA also knows what searches brought people to my sites.
Conclusion
I think that covers everything—though I’ve probably forgotten something. It might sound like a lot, but once you get into a rhythm, adding these extra touches doesn’t take long. And the additional insights you gain make it well worth the effort.
If you’ve built a website recently, I’d love to hear about your approach. What tools and techniques do you swear by? Are there any must-have features or best practices I’ve overlooked? Drop a comment below or get in touch—I’m always keen to learn new tricks and refine my process. And if you’re a small business owner looking for guidance on choosing a web developer, check out my new site—it might just save you from a costly mistake!
The post How I build websites in 2025 appeared first on Davblog.

I’ve been a member of Picturehouse Cinemas for something approaching twenty years. It costs about £60 a year and for that, you get five…
I’ve been a member of Picturehouse Cinemas for something approaching twenty years. It costs about £60 a year and for that, you get five free tickets and discounts on your tickets and snacks. I’ve often wondered whether it’s worth paying for, but in the last couple of years, they’ve added an extra feature that makes it well worth the cost. It’s called Film Club and every week they have two curated screenings that members can see for just £1. On Sunday lunchtime, there’s a screening of an older film, and on a weekday evening (usually Wednesday at the Clapham Picturehouse), they show something new. I’ve got into the habit of seeing most of these screenings.
For most of the year, I’ve been considering a monthly post about the films I’ve seen at Film Club, but I’ve never got around to it. So, instead, you get an end-of-year dump of the almost eighty films I’ve seen.
- Under the Skin [4 stars] 2024-01-14
Starting with an old(ish) favourite. The last time I saw this was a free preview for Picturehouse members, ten years ago. It’s very much a film that people love or hate. I love it. The book is great too (but very different) - Go West [3.5] 2024-01-21
They often show old films as mini-festivals of connected films. This was the first of a short series of Buster Keaton films. I hadn’t seen any of them. Go West was a film where I could appreciate the technical aspects, but I wasn’t particularly entertained - Godzilla Minus One [3] 2024-01-23
Around this time, I’d been watching a few of the modern Godzilla films from the “Monsterverse”. I hadn’t really been enjoying them. But this, unrelated, film was far more enjoyable - Steamboat Bill, Jr. [4] 2024-01-28
Back with Buster Keaton. I enjoyed this one far more. - American Fiction [4] 2024-01-30
Sometimes they’ll show an Oscar contender. I ended up having seen seven of the ten Best Picture nominees before the ceremony – which is far higher than my usual rate. I really enjoyed this one - The Zone of Interest [3] 2024-02-03
Another Oscar contender. I think I wasn’t really in the mood for this. I was tired and found it hard to follow. I should rewatch it at some point. - The General [4] 2024-02-11
More Buster Keaton. I really enjoyed this one – my favourite of the three I watched. I could very easily see myself going down a rabbit hole of obsessing over all of his films - Perfect Days [3.5] 2024-02-15
A film about the life of a toilet cleaner in Tokyo. But written and directed by Wim Wenders – so far better than that description makes it sound - Wicked Little Letters [4] 2024-02-20
I thought this would be more popular than it was. But it vanished pretty much without a trace. It’s a really nice little film about swearing - Nosferatu the Vampyre [3.5] 2024-02-25
The Sunday screenings often give me a chance to catch up with old classics that I haven’t seen before. This was one example. This was the 1979 Werner Herzog version. I should track down the 1922 original before watching the new version early next year - Four Daughters [3.5] 2024-02-29
Because the screenings cost £1, I see everything – no matter what the subject matter is. This is an example of a film I probably wouldn’t have seen without Film Club. But it was a really interesting film about a Tunisian woman who lost two of her daughters when they joined Islamic State - The Persian Version [3.5] 2024-03-07
Another film that I would have missed out on without Film Club. It’s an interesting look into the lives of Iranians in America - Girlhood [3] 2024-03-10
This was the start of another short season of related films. This time it was films made by women about the lives of women and girls. This one was about girl gangs in Paris - Still Walking [3] 2024-03-16
A Japanese family get together to commemorate the death of the eldest son. Things happen, but nothing changes - Zola [3.5] 2024-03-17
I had never heard of this film before, but really enjoyed it. It’s the true story of a stripper who goes on a road trip to Florida and gets involved in… stuff - Late Night with the Devil [3.5] 2024-03-19
I thought this was clever. A horror film that takes place on the set of a late-night chat show. Things go horribly wrong - Set It Off [3.5] 2024-03-24
A pretty standard heist film. But the protagonists are a group of black women. I enjoyed it - Disco Boy [2] 2024-03-27
I really didn’t get this film at all - Girls Trip [3.5] 2024-03-31
Another women’s road trip film. It was fun, but I can’t remember much of it now - The Salt of the Earth [3] 2024-04-07
A documentary about the work of photographer Sebastião Salgado. He was in some bad wars and saw some bad shit - The Teachers’ Lounge [3.5] 2024-04-10
Another film that got an Oscar nod. A well-made drama about tensions in the staff room of a German school. - Do the Right Thing [4] 2024-04-14
I had never seen a Spike Lee film. How embarrassing is that? This was really good (but you all knew that) - Sometimes I Think About Dying [3] 2024-04-17
I really wanted to like this. It was well-made. Daisy Ridley is a really good actress. But it didn’t really go anywhere and completely failed to grip me - The Trouble with Jessica [4] 2024-04-22
Another film that deserved to be more successful than it was. Some great comedy performances by a strong cast. - Rope [4.5] 2024-04-28
A chance to see a favourite film on the big screen for the first time. It’s regarded as a classic for good reason - Blackbird Blackbird Blackberry [3] 2024-04-30
Another film that I just wouldn’t have considered if it wasn’t part of the Film Club programme. I had visited Tbilisi a year earlier, so it was interesting to see a film that was made in Georgia. But, ultimately, it didn’t really grip me - The Cars That Ate Paris [3] 2024-05-12
Another old classic that I had never seen. It’s a bit like a precursor to Mad Max. I’m glad I’ve seen it, but I won’t be rushing to rewatch it - Victoria [3.5] 2024-05-19
This was a lot of fun. The story of one night in the life of a Spanish woman living in Berlin. Lots of stuff happens. It’s over two hours long and was shot in a single, continuous take - The Beast [3.5] 2024-05-22
This was interesting. So interesting that I rewatched it when it appeared on Mubi a few months ago. I’m not sure I can explain it all, but I’ll be rewatching again at some point (and probably revising my score upwards) - Eyes Wide Shut [4] 2024-05-26
I hadn’t seen this for maybe twenty-five years. And I don’t think I ever saw it in a cinema. It’s better than I remember - Rosalie [3.5] 2024-05-28
A film about a bearded lady in 19th-century France. I kid you not. It’s good - All About My Mother [3.5] 2024-06-02
Years ago, I went through a phase of watching loads of Almodóvar films. I was sure I’d seen this one, but I didn’t remember it at all. It’s good though - Àma Gloria [3] 2024-06-04
I misunderstood the trailer for this and was on the edge of my seat throughout waiting for a disaster to happen. But, ultimately, it was a nice film about a young girl visiting her old nanny in Cape Verde - Full Metal Jacket [3.5] 2024-06-09
This really wasn’t as good as I remembered it. Everyone remembers the training camp stuff, but half of the film happens in-country – and that’s all rather dull - Sasquatch Sunset [2] 2024-06-11
I wanted to like this. It would have made a funny two-minute SNL sketch. But it really didn’t work when stretched to ninety minutes - Being John Malkovich [4] 2024-06-16
Still great - Green Border [4] 2024-06-19
A lot of the films I’ve seen at Film Club in previous years seem to be about people crossing borders illegally. This one was about the border between Belarus and Poland. It was very depressing – but very good - Attack the Block [4] 2024-06-23
Another old favourite that it was great to see on the big screen - The 400 Blows [3] 2024-06-30
The French New Wave is a huge hole in my knowledge of cinema, so I was glad to have an opportunity to start putting that right. This, however, really didn’t grip me - Bye Bye Tiberias [2.5] 2024-07-02
Hiam Abbass (who you might know as Marcia in Succession) left her native Palestine in the 80s to live in Paris. This is a documentary following a visit she made back to her family. It didn’t really go anywhere - Breathless [3] 2024-07-07
More French New Wave. I like this more than The 400 Blows – but not much more - After Hours [4] 2024-07-13
Another old favourite from the 80s that I had never seen on the big screen. It’s still great - What Ever Happened to Baby Jane? [2.5] 2024-07-14
This was an object lesson in the importance of judging a film in its context. I know this is a great film, but watching it in the 21st century just didn’t have the impact that watching it in the early 60s would have had - Crossing [3.5] 2024-07-16
A Georgian woman travels to Istanbul to try to find her niece. We learn a lot about the gay and trans communities in the city. I enjoyed this a lot - American Gigolo [3] 2024-07-28
Something else that I had never seen. And, to be honest, I don’t think I had really missed much - Dìdi (弟弟) [3.5] 2024-07-31
Nice little story about a Taiwanese teen growing up in California - I Saw the TV Glow [4] 2024-08-05
I imagine this will be on many “best films of the year” lists. It’s a very strange film about two teens and their obsession with a TV show that closely resembles Buffy the Vampire Slayer. - Hollywoodgate [2.5] 2024-08-13
I really wanted to like this. An Egyptian filmmaker manages to get permission to film a Taliban group that takes over an American base in Afghanistan. But, ultimately, don’t let him film anything interesting and the film is a bit of a disappointment - Beverly Hills Cop [1] 2024-08-18
I had never seen this before. And I wish I still hadn’t. One of the worst films I’ve seen in a very long time - Excalibur [4] 2024-08-25
Another old favourite that I hadn’t seen on the big screen for a very long time. This is the film that gave me an obsession with watching any film that’s based on Arthurian legend, no matter how bad (and a lot of them are very, very bad) - The Quiet Girl [3.5] 2024-09-01
A young Irish girl is sent away to spend the summer with distant relations. She comes to realise that life doesn’t have to be as grim as it usually is for her - Lee [3.5] 2024-09-04
A really good biopic about the American photographer Lee Miller. Kate Winslet is really good as Miller - The Queen of My Dreams [3.5] 2024-09-11
Another film that I wouldn’t have seen without Film Club. A Canadian Pakistani lesbian woman visits Pakistan and learns about some of the cultural pressures that shaped her mother. It’s a lovely film - My Own Private Idaho [2] 2024-09-15
Another film that I had never seen before. Some nice acting by Keanu Reeves and River Phoenix, but this really didn’t interest me - Girls Will Be Girls [3.5] 2024-09-17
A coming-of-age film about a teenage girl in India. I enjoyed this - The Shape of Water [3.5] 2024-09-22
I don’t think I’ve seen this since the year it was released (and won the Best Picture Oscar). I still enjoyed it, but I didn’t think it held up as well as I expected it to - The Banshees of Inisherin [3.5] 2024-09-29
I’d seen this on TV, but you need to see it on a big screen to get the full effect. I’m sure you all know how good it is - The Full Monty [3] 2024-10-06
I never understood why this was so much more popular than Brassed Off which is, to me at least, a far better example of the “British worker fish out of water” genre (that’s not a genre, is it?) I guess it’s the soundtrack and the slightly Beryl Cook overtones – the British love a bit of smut - Timestalker [2.5] 2024-10-08
I really wanted to like this. But if just didn’t grab me. I’ll try it again at some point - Nomadland [3] 2024-10-13
Another Best Picture Oscar winner. And it’s another one where I can really see how important and well-made it is – but it just doesn’t do anything for me - The Apprentice [4] 2024-10-17
I don’t know why Trump was so against this film. I thought he came out of this far more positively than I expected. But it seemed to barely get a release. It has still picked up a few (well-deserved) nominations though - Little Miss Sunshine [4] 2024-10-20
Another old favourite. I loved seeing this again - Stoker [3] 2024-10-27
I had never seen this before. I can’t quite put my finger on it, but I didn’t really enjoy it - Anora [4] 2024-10-29
This was probably the best film I saw this year. Well, certainly the best new film. It’s getting a lot of awards buzz. I hope it does well - (500) Days of Summer [4] 2024-11-03
I don’t think I had seen this since soon after it was released. It was great to see it again - Bird [3] 2024-11-05
This was slightly strange. I’ve seen a few films about the grimness of life on council estates. But this one threw in a bit of magical realism that didn’t really work for me - Sideways [3.5] 2024-11-10
Another film I hadn’t watched for far too long - Sunshine [4] 2024-11-17
This is one of my favourite recent(ish) scifi films. I saw it on the Science Museum’s IMAX screen in 2023, but I wasn’t going to skip the chance to see it again - Conclave [3.5] 2024-11-19
Occasionally, this series gives you a chance to see something that’s going to be up for plenty of awards. This was a good example. I enjoyed it - The Grand Budapest Hotel [4] 2024-11-24
I’ve been slightly disappointed with a few recent Wes Anderson films, so it was great to have the opportunity to see one of his best back on the big screen - The Universal Theory [4] 2024-11-26
I knew nothing about this going into it. And it was a fabulous film. Mysteries and quantum physics in the Swiss Alps. And all filmed in black and white. This didn’t get the coverage it deserved. - Home Alone [2] 2024-12-08
I thought I had never seen this before. But apparently I logged watching it many years ago. I know everyone loves it, but I couldn’t see the point - The Apartment [4] 2024-12-15
This was interesting. I have a background quest to watch all of the Best Picture Oscar winners and I hadn’t seen this one. I knew absolutely nothing about it. I thought it was really good - The Taste of Things [3.5] 2024-12-21
A film that I didn’t get to see earlier in the year. It’s largely about cooking in a late-nineteenth century French country kitchen. It would make an interesting watch alongside The Remains of the Day - Christmas Eve in Miller’s Point [2] 2024-12-24
I didn’t understand this at all. It went nowhere and said nothing interesting. A large family meets up for their traditional Christmas Eve. No-one enjoys themself - La Chimera [2] 2024-12-29
And finishing on a bit of a low. I don’t understand why this got so many good reviews. Maybe I just wasn’t in the right mood for it. Something about criminals looking for ancient relics in Italy
The post Picturehouse Film Club appeared first on Davblog.
Royal Titles Decoded: What Makes a Prince or Princess? — Line of Succession Blog

Royal titles in the United Kingdom carry a rich tapestry of history, embodying centuries of tradition while adapting to the changing landscape of the modern world. This article delves into the structure of these titles, focusing on significant changes made during the 20th and 21st centuries, and how these rules affect current royals.
The Foundations: Letters Patent of 1917
The framework for today’s royal titles was significantly shaped by the Letters Patent issued by King George V in 1917. This document was pivotal in redefining who in the royal family would be styled with “His or Her Royal Highness” (HRH) and as a prince or princess. Specifically, the 1917 Letters Patent restricted these styles to:
- The sons and daughters of a sovereign.
- The male-line grandchildren of a sovereign.
- The eldest living son of the eldest son of the Prince of Wales.
This move was partly in response to the anti-German sentiment of World War I, aiming to streamline the monarchy and solidify its British identity by reducing the number of royals with German titles.
Notice that the definitions talk about “a sovereign”, not “the sovereign”. This means that when the sovereign changes, no-one will lose their royal title (for example, Prince Andrew is still the son of a sovereign, even though he is no longer the son of the sovereign). However, people can gain royal titles when the sovereign changes — we will see examples below.
Extension by George VI in 1948
Understanding the implications of the existing rules as his family grew, King George VI issued a new Letters Patent in 1948 to extend the style of HRH and prince/princess to the children of the future queen, Princess Elizabeth (later Queen Elizabeth II). This was crucial as, without this adjustment, Princess Elizabeth’s children would not automatically have become princes or princesses because they were not male-line grandchildren of the monarch. This ensured that Charles and Anne were born with princely status, despite being the female-line grandchildren of a monarch.
The Modern Adjustments: Queen Elizabeth II’s 2012 Update
Queen Elizabeth II’s update to the royal titles in 2012 before the birth of Prince William’s children was another significant modification. The Letters Patent of 2012 decreed that all the children of the eldest son of the Prince of Wales would hold the title of HRH and be styled as prince or princess, not just the eldest son. This move was in anticipation of changes brought about by the Succession to the Crown Act of 2013, which ended the system of male primogeniture, ensuring that the firstborn child of the Prince of Wales, regardless of gender, would be the direct heir to the throne. Without this change, there could have been a situation where Prince William’s first child (and the heir to the throne) was a daughter who wasn’t a princess, whereas her eldest (but younger) brother would have been a prince.
Impact on Current Royals
- Children of Princess Anne: When Anne married Captain Mark Phillips in 1973, he was offered an earldom but declined it. Consequently, their children, Peter Phillips and Zara Tindall, were not born with any titles. This decision reflects Princess Anne’s preference for her children to have a more private life, albeit still active within the royal fold.
- Children of Prince Edward: Initially, Prince Edward’s children were styled as children of an earl, despite his being a son of the sovereign. Recently, his son James assumed the courtesy title Earl of Wessex, which Prince Edward will inherit in due course from Prince Philip’s titles. His daughter, Lady Louise Windsor, was also styled in line with Edward’s wish for a lower-profile royal status for his children.
- Children of Prince Harry: When Archie and Lilibet were born, they were not entitled to princely status or HRH. They were great-grandchildren of the monarch and, despite the Queen’s adjustments in 2012, their cousins — George, Charlotte and Louis — were the only great-grandchildren of the monarch with those titles. When their grandfather became king, they became male-line grandchildren of a monarch and, hence, a prince and a princess. It took a while for those changes to be reflected on the royal family website. This presumably gave the royal household time to reflect on the effect of the children’s parents withdrawing from royal life and moving to the USA.
Special Titles: Prince of Wales and Princess Royal
- Prince of Wales: Historically granted to the heir apparent, this title is not automatic and needs to be specifically bestowed by the monarch. Prince Charles was created Prince of Wales in 1958, though he had been the heir apparent since 1952. Prince William, on the other hand, received the title in 2022 — just a day after the death of Queen Elizabeth II.
- Princess Royal: This title is reserved for the sovereign’s eldest daughter but is not automatically reassigned when the previous holder passes away or when a new eldest daughter is born. Queen Elizabeth II was never Princess Royal because her aunt, Princess Mary, held the title during her lifetime. Princess Anne currently holds this title, having received it in 1987.
The Fade of Titles: Distant Royals
As the royal family branches out, descendants become too distanced from the throne, removing their entitlement to HRH and princely status. For example, the Duke of Gloucester, Duke of Kent, Prince Michael of Kent and Princess Alexandra all have princely status as male-line grandchildren of George V. Their children are all great-grandchildren of a monarch and, therefore, do not all have royal styles or titles. This reflects a natural trimming of the royal family tree, focusing the monarchy’s public role on those directly in line for succession.
Conclusion
The evolution of British royal titles reflects both adherence to deep-rooted traditions and responsiveness to modern expectations. These titles not only delineate the structure and hierarchy within the royal family but also adapt to changes in societal norms and the legal landscape, ensuring the British monarchy remains both respected and relevant in the contemporary era.
Originally published at https://blog.lineofsuccession.co.uk on April 25, 2024.
Royal Titles Decoded: What Makes a Prince or Princess? — Line of Succession Blog was originally published in Line of Succession on Medium, where people are continuing the conversation by highlighting and responding to this story.

Changing rooms are the same all over the galaxy and this one really played to the stereotype. The lights flickered that little bit more than you’d want them to, a sizeable proportion of the lockers wouldn’t lock and the whole room needed a good clean. It didn’t fit with the eye-watering amount of money we had all paid for the tour.
There were a dozen or so of us changing from our normal clothes into outfits that had been supplied by the tour company — outfits that were supposed to render us invisible when we reached our destination. Not invisible in the “bending light rays around you” way, they would just make us look enough like the local inhabitants that no-one would give us a second glance.
Appropriate changing room etiquette was followed. Everyone was either looking at the floor or into their locker to avoid eye contact with anyone else. People talked in lowered voices to people they had come with. People who, like me, had come alone were silent. I picked up on some of the quiet conversations — they were about the unusual flora and fauna of our location and the unique event we were here to see.
Soon, we had all changed and were ushered into a briefing room where our guide told us many things we already knew. She had slides explaining the physics behind the phenomenon and was at great pains to emphasise the uniqueness of the event. No other planet in the galaxy had been found that met all of the conditions for what we were going to see. She went through the history of tourism to this planet — decades of uncontrolled visits followed by the licensing of a small number of carefully vetted companies like the one we were travelling with.
She then turned to more practical matters. She reiterated that our outfits would allow us to pass for locals, but that we should do all we could to avoid any interactions with the natives. She also reminded us that we should only look at the event through the equipment that we would be issued with on our way down to the planet.
Through a window in the briefing room a planet, our destination, hung in space. Beyond the planet, its star could also be seen.
An hour or so later, we were on the surface of the planet. We were deposited at the top of a grassy hill on the edge of a large crowd of the planet’s inhabitants. Most of us were of the same basic body shape as the quadruped locals and, at first glance at least, passed for them. A few of us were less lucky and had to stay in the vehicles to avoid suspicion.
The timing of the event was well understood and the company had dropped us off early enough that we were able to find a good viewing spot but late enough that we didn’t have long to wait. We had been milling around for half an hour or so when a palpable moment of excitement passed through the crowd and everyone looked to the sky.
Holding the equipment I had been given to my eyes I could see what everyone else had noticed. A small bite seemed to have been taken from the bottom left of the planet’s sun. As we watched, the bite got larger and larger as the planet’s satellite moved in front of the star. The satellite appeared to be a perfect circle, but at the last minute — just before it covered the star completely — it became obvious that the edge wasn’t smooth as gaps between irregularities on the surface (mountains, I suppose) allowed just a few points of light through.
And then the satellite covered the sun and the atmosphere changed completely. The world turned dark and all conversations stopped. All of the local animals went silent. It was magical.
My mind went back to the slides explaining the phenomenon. Obviously, the planet’s satellite and star weren’t the same size, but their distance from the planet exactly balanced their difference in size so they appeared the same size in the sky. And the complex interplay of orbits meant that on rare occasions like this, the satellite would completely and exactly cover the star.
That was what we were there for. This was what was unique about this planet. No other planet in the galaxy had a star and a satellite that appeared exactly the same size in the sky. This is what made the planet the most popular tourist spot in the galaxy.
Ten minutes later, it was over. The satellite continued on its path and the star was gradually uncovered. Our guide bundled us into the transport and back up to our spaceship.
Before leaving the vicinity of the planet, our pilot found three locations in space where the satellite and the star lined up in the same way and created fake eclipses for those of us who had missed taking photos of the real one.
Originally published at https://blog.dave.org.uk on April 7, 2024.
Changing rooms are the same all over the galaxy and this one really played to the stereotype. The lights flickered that little bit more than you’d want them to, a sizeable proportion of the lockers wouldn’t lock and the whole room needed a good clean. It didn’t fit with the eye-watering amount of money we had all paid for the tour.
There were a dozen or so of us changing from our normal clothes into outfits that had been supplied by the tour company – outfits that were supposed to render us invisible when we reached our destination. Not invisible in the “bending light rays around you” way, they would just make us look enough like the local inhabitants that no-one would give us a second glance.
Appropriate changing room etiquette was followed. Everyone was either looking at the floor or into their locker to avoid eye contact with anyone else. People talked in lowered voices to people they had come with. People who, like me, had come alone were silent. I picked up on some of the quiet conversations – they were about the unusual flora and fauna of our location and the unique event we were here to see.
Soon, we had all changed and were ushered into a briefing room where our guide told us many things we already knew. She had slides explaining the physics behind the phenomenon and was at great pains to emphasise the uniqueness of the event. No other planet in the galaxy had been found that met all of the conditions for what we were going to see. She went through the history of tourism to this planet – decades of uncontrolled visits followed by the licensing of a small number of carefully vetted companies like the one we were travelling with.
She then turned to more practical matters. She reiterated that our outfits would allow us to pass for locals, but that we should do all we could to avoid any interactions with the natives. She also reminded us that we should only look at the event through the equipment that we would be issued with on our way down to the planet.
Through a window in the briefing room a planet, our destination, hung in space. Beyond the planet, its star could also be seen.
An hour or so later, we were on the surface of the planet. We were deposited at the top of a grassy hill on the edge of a large crowd of the planet’s inhabitants. Most of us were of the same basic body shape as the quadruped locals and, at first glance at least, passed for them. A few of us were less lucky and had to stay in the vehicles to avoid suspicion.
The timing of the event was well understood and the company had dropped us off early enough that we were able to find a good viewing spot but late enough that we didn’t have long to wait. We had been milling around for half an hour or so when a palpable moment of excitement passed through the crowd and everyone looked to the sky.
Holding the equipment I had been given to my eyes I could see what everyone else had noticed. A small bite seemed to have been taken from the bottom left of the planet’s sun. As we watched, the bite got larger and larger as the planet’s satellite moved in front of the star. The satellite appeared to be a perfect circle, but at the last minute – just before it covered the star completely – it became obvious that the edge wasn’t smooth as gaps between irregularities on the surface (mountains, I suppose) allowed just a few points of light through.
And then the satellite covered the sun and the atmosphere changed completely. The world turned dark and all conversations stopped. All of the local animals went silent. It was magical.
My mind went back to the slides explaining the phenomenon. Obviously, the planet’s satellite and star weren’t the same size, but their distance from the planet exactly balanced their difference in size so they appeared the same size in the sky. And the complex interplay of orbits meant that on rare occasions like this, the satellite would completely and exactly cover the star.
That was what we were there for. This was what was unique about this planet. No other planet in the galaxy had a star and a satellite that appeared exactly the same size in the sky. This is what made the planet the most popular tourist spot in the galaxy.
Ten minutes later, it was over. The satellite continued on its path and the star was gradually uncovered. Our guide bundled us into the transport and back up to our spaceship.
Before leaving the vicinity of the planet, our pilot found three locations in space where the satellite and the star lined up in the same way and created fake eclipses for those of us who had missed taking photos of the real one.
The post The Tourist appeared first on Davblog.
I really thought that 2023 would be the year I got back into the swing of seeing gigs. But, somehow I ended up seeing even fewer than I did in 2022 – 12, when I saw 16 the previous year. Sometimes, I look at Martin’s monthly gig round-ups and wonder what I’m doing with my life!
I normally list my ten favourite gigs of the year, but it would be rude to miss just two gigs from the list, so here are all twelve gigs I saw this year – in, as always, chronological order.
- John Grant (supported by The Faultress) at St. James’s Church
John Grant has become one of those artists I try to see whenever they pass through London. And this was a particularly special night as he was playing an acoustic set in one of the most atmospheric venues in London. The evening was only slightly marred by the fact I arrived too late to get a decent seat and ended up not being able to see anything. - Hannah Peel at Kings Place
Hannah Peel was the artist in residence at Kings Place for a few months during the year and played three gigs during that time. This was the first of them – where she played her recent album, Fir Wave, in its entirety. A very laid-back and thoroughly enjoyable evening. - Orbital at the Eventim Apollo
I’ve been meaning to get around to seeing Orbital for many years. This show was originally planned to be at the Brixton Academy but as that venue is currently closed, it was relocated to Hammersmith. To be honest, this evening was slightly hampered by the fact I don’t know as much of their work as I thought I did and it was all a bit samey. I ended up leaving before the encore. - Duran Duran (supported by Jake Shears) at the O2 Arena
Continuing my quest to see all of the bands I was listening to in the 80s (and, simultaneously, ticking off the one visit to the O2 that I allow myself each year). I really enjoyed the nostalgia of seeing Duran Duran but, to be honest, I think I enjoyed Jake Shears more – and it was the Scissor Sisters I was listening to on the way home. - Hannah Peel and Beibei Wang at Kings Place
Even in a year where I only see a few gigs, I still manage to see artists more than once. This was the second of Hannah Peel’s artist-in-residence shows. She appeared with Chinese percussionist Beibei Wang in a performance that was completely spontaneous and unrehearsed. Honestly, some parts were more successful than others, but it was certainly an interesting experience. - Songs from Summerisle at the Barbican Hall
The Wicker Man is one of my favourite films, so I jumped at the chance to see the songs from the soundtrack performed live. But unfortunately, the evening was a massive disappointment. The band sounded like they had met just before the show and, while they all obviously knew the songs, they hadn’t rehearsed them together. Maybe they were going for a rustic feel – but, to me, it just sounded unprofessional. - Belle and Sebastian at the Roundhouse
Another act that I try to see as often as possible. I know some people see Belle and Sebastian as the most Guardian-reader band ever – but I love them. This show saw them on top form. - Jon Anderson and the Paul Green Rock Academy at the Shepherds Bush Empire
I’ve seen Yes play live a few times in the last ten years or so and, to be honest, it can sometimes be a bit over-serious and dull. In this show, Jon Anderson sang a load of old Yes songs with a group of teenagers from the Paul Green Rock Academy (the school that School of Rock was based on) and honestly, the teenagers brought such a feeling of fun to the occasion that it was probably the best Yes-related show that I’ve seen. - John Grant and Richard Hawley at the Barbican Hall
Another repeated act – my second time seeing John Grant in a year. This was something different as he was playing a selection of Patsy Cline songs. I don’t listen to Patsy Cline much, but I knew a few more of the songs than I expected to. This was a bit lower-key than I was expecting. - Peter Hook and the Light at the Eventim Apollo
I’ve been planning to see Peter Hook and the Light for a couple of years. There was a show I had tickets for in 2020, but it was postponed because of COVID and when it was rescheduled, I was unable to go, so I cancelled my ticket and got a refund. So I was pleased to get another chance. And this show had them playing both of the Substance albums (Joy Division and New Order). I know New Order still play some Joy Division songs in their sets, but this is probably the best chance I’ll have to see some deep Joy Division cuts played live. I really enjoyed this show. - Heaven 17 at the Shepherds Bush Empire
It seems I see Heaven 17 live most years and they usually appear on my “best of” lists. This show was celebrating the fortieth anniversary of their album The Luxury Gap – so that got played in full, alongside many other Heaven 17 and Human League songs. A thoroughly enjoyable night. - The Imagined Village and Afro-Celt Sound System at the Roundhouse
I’ve seen both The Imagined Village and the Afro-Celts live once before. And they were two of the best gigs I’ve ever seen. I pretty much assumed that the death of Simon Emmerson (who was an integral part of both bands) earlier in 2023 would mean that both bands would stop performing. But this show was a tribute to Emmerson and the bands both reformed to celebrate his work. This was probably my favourite gig of the year. That’s The Imagined Village (featuring two Carthys, dour Coppers and Billy Bragg) in the photo at the top of this post.
So, what’s going to happen in 2024. I wonder if I’ll get back into the habit of going to more shows. I only have a ticket for one gig next year – They Might Be Giants playing Flood in November (a show that was postponed from this year). I guess we’ll see. Tune in this time next year to see what happened.
The post 2023 in Gigs appeared first on Davblog.

author: Michael Ruhlman
name: David
average rating: 4.06
book published: 2009
rating: 0
read at:
date added: 2023/02/06
shelves: currently-reading
review:






author: J.J. Abrams
name: David
average rating: 3.86
book published: 2013
rating: 0
read at:
date added: 2022/01/16
shelves: currently-reading
review:

author: Beth Buelow
name: David
average rating: 3.37
book published: 2015
rating: 0
read at:
date added: 2020/01/27
shelves: currently-reading
review:

Some thoughts on ways to measure the quality of Perl code (and, hence, get a basis for improving it)

How (and why) I spent 90 minutes writing a Twitterbot that tweeted the Apollo 11 mission timeline (shifted by 50 years)

A talk from the European Perl Conference 2019 (but not about Perl)

author: Lindsey Bareham
name: David
average rating: 4.50
book published: 1999
rating: 0
read at:
date added: 2019/07/29
shelves: currently-reading
review:

The slides from a half-day workshop on career development for programmers that I ran at The Perl Conference in Glasgow

A (not entirely serious) talk that I gave at the London Perl Mongers technical meeting in March 2018. It talks about how and why I build a web site listing the line of succession to the British throne back through history.